Imagine you're handed a hundred things to remember, and exactly ten lockers to keep them in. One thing per locker is easy, but you'd have to throw away ninety of them. What do you do?
The obvious answer is to give up gracefully: fill your ten lockers, accept that the other ninety are gone. But there's a stranger option. What if you smeared all one hundred things faintly across all ten lockers, a little of everything everywhere, so that nothing is stored perfectly, but everything is partly recoverable?
That second strategy has a name in machine learning: superposition. It sounds like it shouldn't work. This post is about a small experiment that shows not only that it works, but exactly how a neural network pulls it off, and why understanding this toy is a stepping stone to understanding why the neurons inside real language models are so maddeningly hard to interpret.
the setupThe impossible assignment
The experiment is deliberately minimal. We build a tiny network: 100 inputs, a single hidden layer of just 10 neurons, and 100 outputs. No bias terms, no shortcuts. Its only job is to copy its input to its output, to take in 100 "features" and faithfully reproduce them.
The catch is the bottleneck. To get from 100 inputs to 100 outputs, everything has to squeeze through those 10 neurons in the middle. There is simply no room to give each feature its own dedicated neuron; there are ten times too few. Something has to give.
The saving grace is sparsity. In training, each of the 100 features
is switched on only rarely, with probability p = 0.02, meaning that in
any given example only about two features are active at once. The network
never has to reconstruct all 100 things simultaneously. It just has to be ready for
whichever few show up. That single fact, as we'll see, is what makes the impossible
assignment possible.
Ten lockers, a hundred items, but you only ever reach for two at a time. Suddenly smearing everything everywhere doesn't sound so crazy.
part 1Does it even work?
Before admiring the strategy, we should check it beats the lazy alternative. Call that the naive baseline: dedicate each of the 10 neurons to one feature, nail those 10 perfectly, and output zero for the other 90. It's the "fill your lockers and give up" plan.
We measure quality with error: how far each reconstructed feature lands from the truth (lower is better). The naive plan posts an average error of 0.151. The trained network, given the same ten neurons but allowed to learn freely, comes in at 0.074, roughly half.
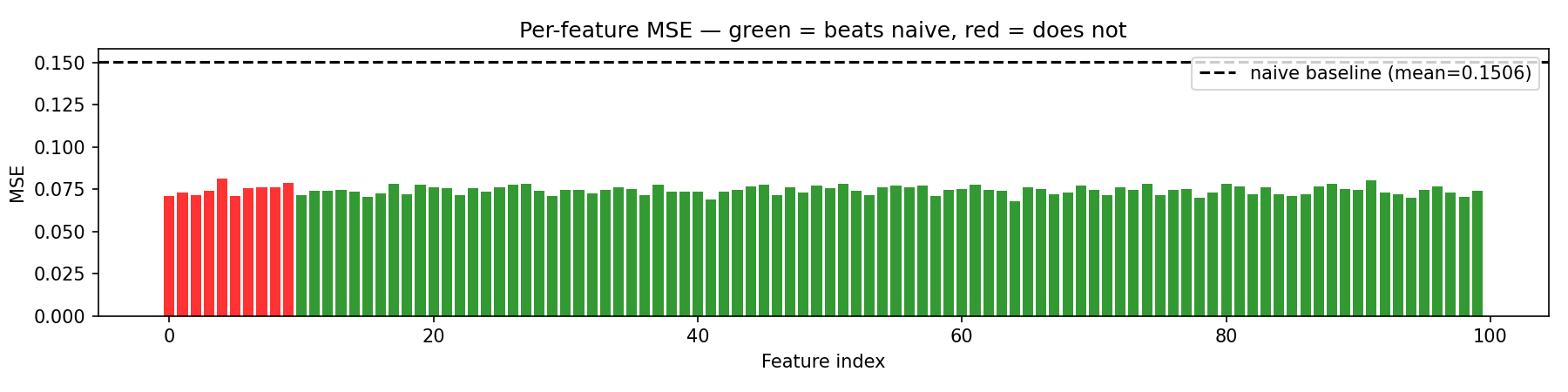
That picture captures the whole bargain. The trained network sacrifices the handful
of features it could have aced, in exchange for doing a decent job on
everything. Why is that worth it? Because of how the network is scored. The
training loss here is L4: it penalizes errors raised to the fourth
power, so a single huge mistake hurts far more than many small ones. Ignoring 90
features entirely produces 90 huge mistakes. Spreading the pain thin is, mathematically,
the better deal.
part 2What it learned: a faint copy of everything
So the network covers all 100 features. But what does "covering" actually look like? If you feed in one feature on its own and watch its output, you get a clean, simple shape every time: a straight line through the origin, the right shape, just dialed down in volume.
Each feature comes out scaled by a slope. A perfect copy would have slope 1.0. Across all 100 features, the average slope is about 0.38: every feature is replayed at roughly 38% of full volume. The remarkable part is how little that number varies.
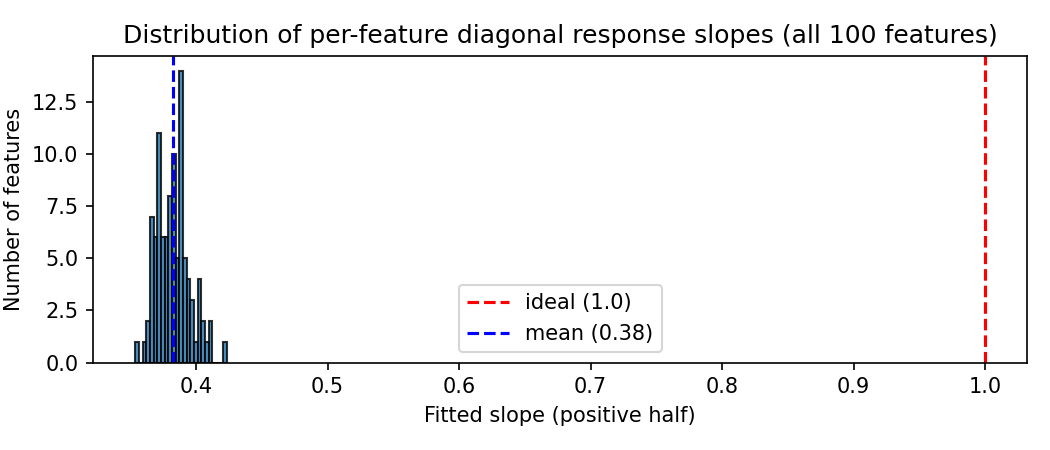
This is the first genuine surprise. You might expect the network to play favorites, serving some features loud and clear while neglecting others. It doesn't. It learned one democratic compromise and applied it almost identically to all 100. Earlier plots of a few "best" and "worst" features looked different, but that was a trick of small samples; measured across the whole set, they're treated the same.
part 3The hidden cost: interference
Smearing everything across shared neurons has a price. If features pass through the same ten neurons, then switching on one feature inevitably nudges the outputs of others. These accidental nudges are called cross-terms, and they come in two flavors.
Some are cooperative: turning on one feature gives a few others a small free boost toward their correct value. Others are destructive: the strongest one found here, activating feature 12, actively suppresses feature 15's output. That's not harmless dilution: it's one feature stepping on another.
Here's the twist that makes the whole scheme survive: remember that only about two features are ever on at once. Most of these collisions simply never get triggered simultaneously. Sparsity is the safety margin that turns a reckless strategy into a viable one.
part 4Looking under the hood
We can make the routing concrete. The network's two layers can be folded into a
single 100×100 grid of numbers, M, that summarizes how every input
feature gets mapped to every output feature. Plot it and the strategy jumps out.
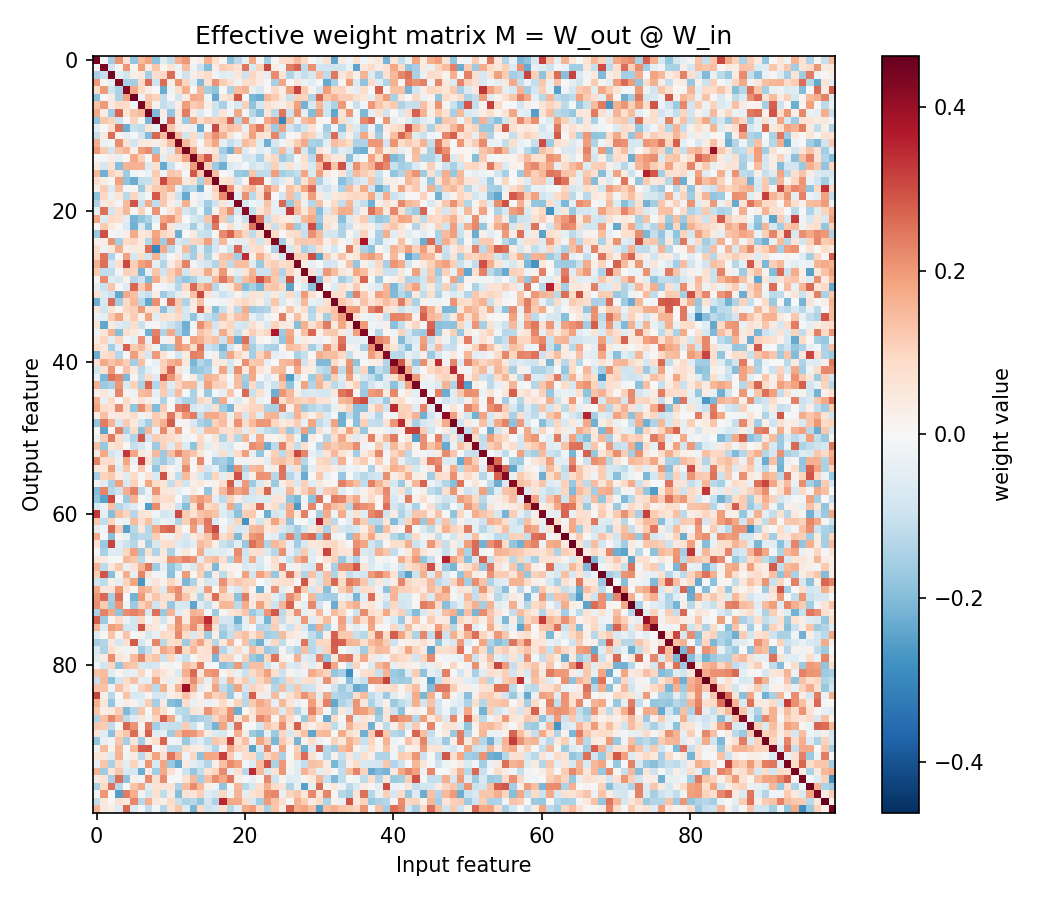
Two things stand out. First, this grid has a rank of exactly 10, a precise mathematical fingerprint that the network is using every last scrap of its ten-neuron budget, holding nothing in reserve. Second, look at how much of the grid is off the diagonal. Add up all that interference and it's nearly 25 times larger than the clean diagonal signal.
Then comes the most elegant result in the whole study. You'd guess that the features suffering the most error are the ones absorbing the most interference. So we checked whether a feature's "interference load" predicts its error. The correlation is 0.10, essentially nothing.
Why? Because every feature receives almost exactly the same amount of interference. The network didn't just spread the signal evenly; it spread the damage evenly too. There's no unlucky feature stuck holding everyone else's noise. It's a strikingly fair arrangement, and the network arrived at it on its own, purely from gradient descent.
part 5Every neuron is a generalist
Now to the question that connects this toy to the real world. In a network we can interpret, each neuron would mean something: "this one detects feature 7." A neuron like that is called monosemantic: one neuron, one meaning. The opposite, a neuron that's a little bit involved in everything, is polysemantic, and those are the ones that make AI models so hard to decode.
So which kind did our ten neurons become? We can score each one from 1 (perfectly monosemantic) to near 0 (fully spread out). All ten neurons land between 0.05 and 0.08, about as polysemantic as it is possible to be.
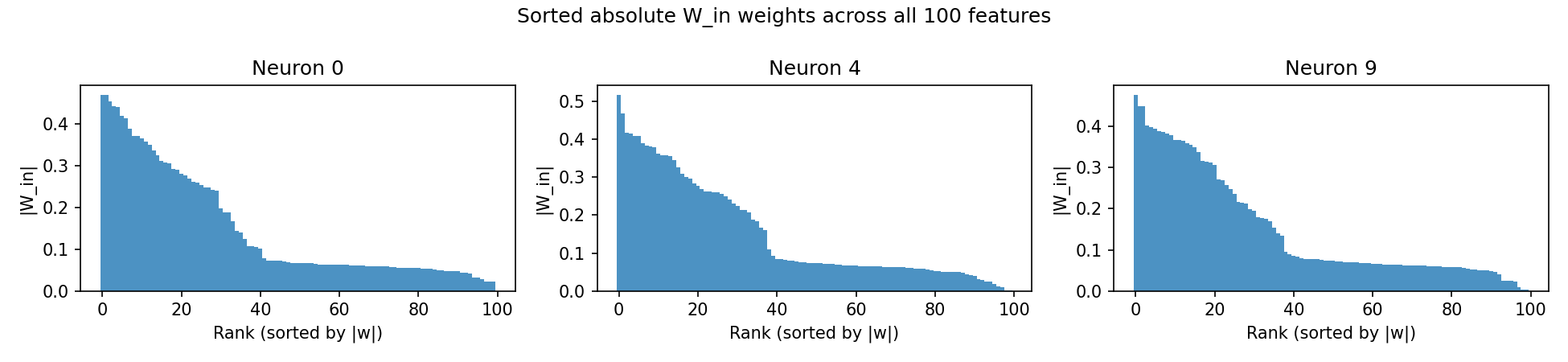
With a generous definition of "connected," every neuron touches nearly 90 of the 100 features. The ten neurons are essentially interchangeable: ten identical generalists, each doing a faint slice of everything. There is no neuron you could point to and say "that one is for feature 42." And that is the whole problem with interpreting neurons in miniature: the network's knowledge isn't stored in the neurons, it's stored in the pattern across them.
part 6How gracefully does it break?
The network was trained on sparse inputs, about two features at a time. What happens when we overload it and switch on more at once? If the destructive collisions compounded, we'd expect a sudden cliff. Instead, the error rises in an almost perfectly straight line as the load increases.
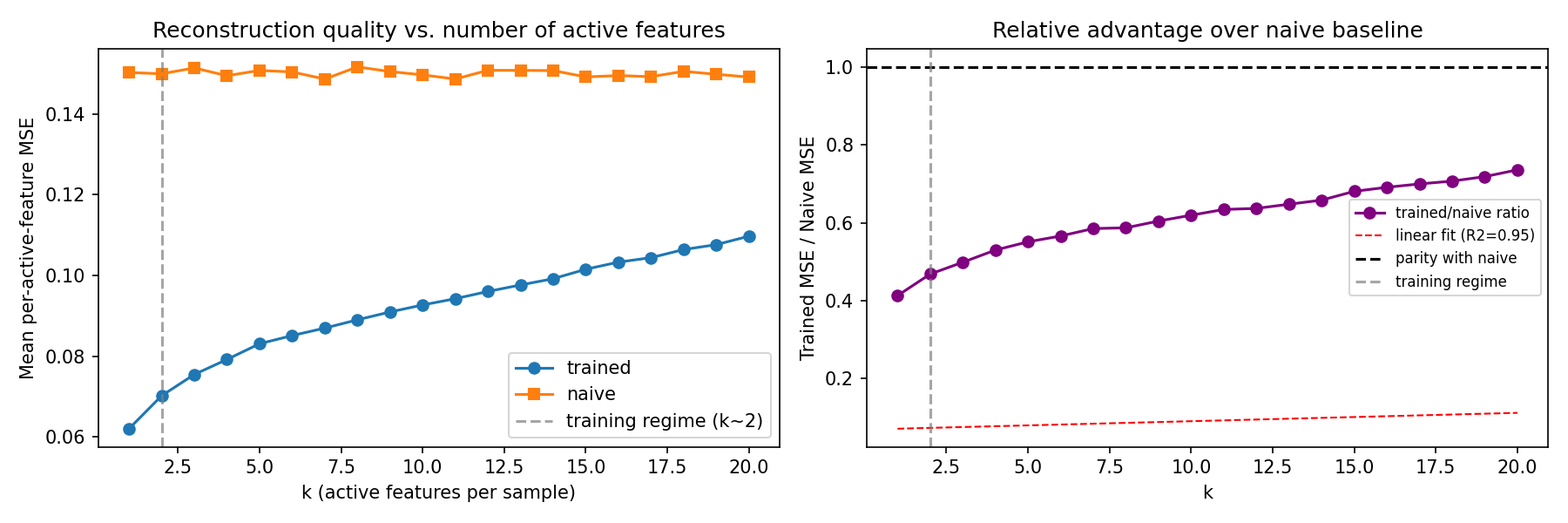
That straight line is reassuring: each extra active feature adds a roughly constant dose of noise rather than triggering a chain reaction. The shared strategy degrades, but it degrades politely, and it stays ahead of the give-up baseline even when badly overloaded.
part 7The fingerprint of fairness
One last test. Weights tell us what a neuron is connected to, but not what it actually does, because the network's nonlinearity can let a neuron influence features it's barely wired to. So we go causal: silence one neuron, see which features get worse, and which, tellingly, get better.
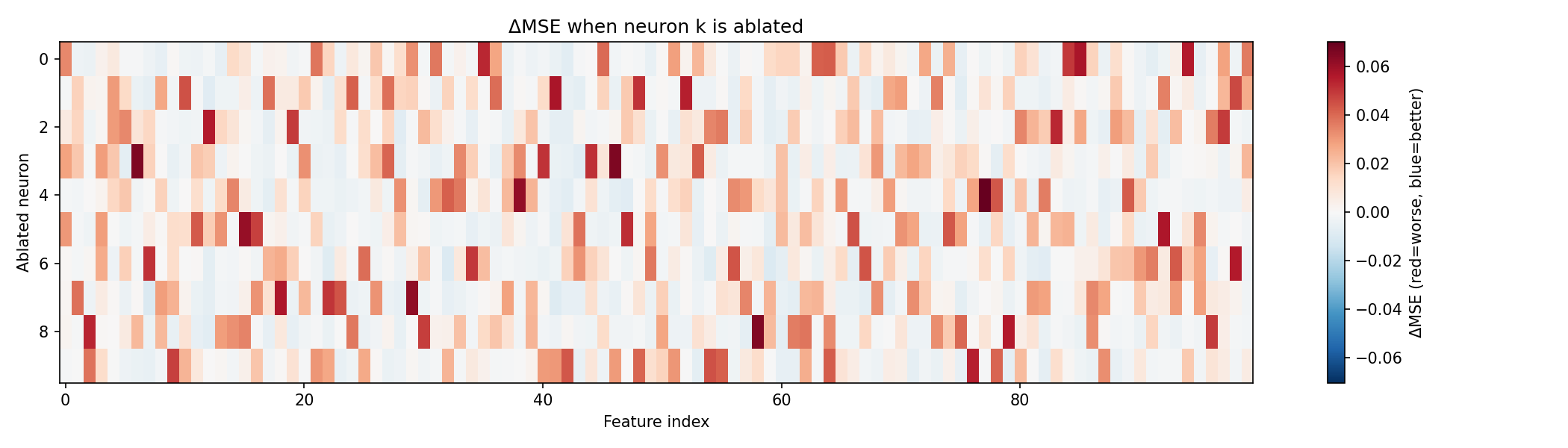
Every one of the ten neurons improves some features when removed. The interference isn't the fault of one or two badly-behaved neurons; it's structural and universal. Carrying a hundred features in ten neurons means every neuron is constantly stepping on some toes as the price of covering others.
Finally, we asked whether the neurons secretly team up, whether pairs of them gang up to damage the same features, which would hint at some higher-level organization. Comparing every pair's "damage list," the typical overlap is just 0.20. Any two neurons hurt almost entirely different sets of features.
the takeawayWhy a toy matters
Step back and the picture is clean. Faced with ten times too few neurons, this network didn't compromise halfway. It committed fully to sharing: every feature replayed at the same faint 38% volume, every neuron a generalist, interference and signal both spread with almost suspicious fairness, and the whole thing held together by the fact that only a couple of features are ever active at once.
This is a deliberately tiny model, but it's a clear window into something that happens in the enormous ones. Real language models also have far more concepts to represent than they have neurons, and they appear to lean on the same trick, packing many features into shared, overlapping directions. That's a big part of why a single neuron in a large model so rarely corresponds to a single clean idea. The meaning lives in the superposition. If we want to read what these models are thinking, this little ten-neuron puzzle is the kind of thing we have to understand first.
The six findings, in brief
- Every neuron is polysemantic, encoding all 100 features faintly, not a few features loudly.
- Each feature comes back as a scaled copy at ~38% volume, nearly identical across all 100.
- The folded weight map uses all 10 neurons (rank 10), with ~25× more interference than signal, survivable only because inputs are sparse.
- Gradient descent rediscovered the classic "tied weights" solution on its own, with the decoder ~13% stronger than the encoder.
- Error grows linearly as more features activate, and beats the give-up baseline even at ten times the training density.
- Every neuron helps some features by hurting others, and those interference footprints are spread independently, with no hidden clusters.
Where this goes next
The neat thing about a toy this small is that you can keep turning the knobs. Swapping
the L4 loss for a gentler one should tempt the network to start playing
favorites. Sweeping the sparsity should reveal the exact tipping point where sharing
stops paying off and giving up wins. Making some features matter more than others
should crack the perfect fairness and force real structure to appear. Each of those is
a clean experiment, and each one tells us a little more about the rules that govern
how networks decide what to remember.
← back to all writing